![[파이썬 개념 정리 8]Seaborn 라이브러리를 이용한 시각화 개념](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fnf9GD%2FbtsInxaJjoB%2FD59OvMSPFp5HyREdgVAnnk%2Fimg.png)

이번 글은 코드잇 강의를 수강하면서 배운 내용을 주로 하여 정리되어 있습니다. (코드잇 스프린트 데이터 애널리스트 트랙 1기 훈련생)
Seaborn 라이브러리
Seaborn 라이브러리는 통계 정보 시각화 라이브러리로 간결한 코드로 그래프 생성하는 기능을 제공합니다.
- Matplotlib보다 근사한 그래프를 쉽게 그릴 수 있는 라이브러리
- Matplotlib과 Seaborn의 차이
- Seaborn : 간편하게 근사한 그래프 생성
- Matplotlib : 원하는대로 커스텀하게 그래프 생성
# seaborn 라이브러리로 그래프를 그리기 전에 필요한 라이브러리 호출
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt바 그래프 (bar)


# 검은색 막대기를 없애고 싶으면 errorbar=None 사용
sns.barplot(data=데이터프레임명, x='컬럼명', y='컬럼명', errorbar=None)
plt.show()
# 그래프의 설정을 조정하고 꾸미고 싶다면 sns.set_theme() 활용
# figure.figsize가 그래프 크기를 가로 길이를 8인치, 세로 길이를 4인치로 조정 / style은 배경색을 조정
sns.set_theme(rc={'figure.figsize': (8,4)}, style='white')
sns.barplot(data=데이터프레임명, x='컬럼명', y='컬럼명', errorbar=None)
plt.show())

sns.set_theme(rc={'figure.figsize': (8,4)}, style='white')
sns.barplot(data=데이터프레임명, x='컬럼명1', y='컬럼명2',hue='컬럼명3(데이터가 이산형인 경우)',errorbar=None)
# 이산형 값들로 이루어진 칼럼을 통해 칼렴3 별로 분포를 볼 수 있다.
plt.show())선 그래프 (line)

sns.set_theme(rc={'figure.figsize': (8,4)}, style='white')
sns.lineplot(data=데이터프레임명, x='컬럼명1', y='컬럼명2',errorbar=None)
plt.show())
sns.set_theme(rc={'figure.figsize': (8,4)}, style='white')
sns.lineplot(data=데이터프레임명, x='컬럼명1', y='컬럼명2',hue='컬럼명3(데이터가 이산형인 경우)',errorbar=None)
plt.show())sns.set_theme() 함수로 그래프 커스터마이징하기
# 그래프 기본 스타일 설정하기
sns.set_theme(style='white') # 색깔은 white, dark, whitegrid, ticks(흰색 바탕의 그래프에 x축과 y축에 눈금이 생김) 등등 가능하다.
# 폰트 설정하기
# Windows
sns.set_theme(style='white', font='Malgun Gothic')
# Mac
sns.set_theme(style='white', font='AppleGothic')
# 폰트 크기 설정하기
sns.set_theme(style='white', font='AppleGothic', font_scale=2)
#팔레트 설정하기 (그래프에서 사용할 색들 설정하기)
sns.set_theme(palette='muted') # pallette의 종류에는 deep(기본값), pastel, muted, bright, dark, colorblind 등이 있다.
#그래프 크기 조절하기
sns.set_theme(rc={'figure.figsize': (12, 6)}
#여러개의 파라미터를 한번에 설정하기
sns.set_theme(style='white', font='AppleGothic', palette='pastel', rc={'figure.figsize': (12, 6)})stripplot


sns.stripplot(data=데이터프레임명, x='컬럼명1', y='컬럼명2')
plt.show())
sns.stripplot(data=데이터프레임명, x='컬럼명1', y='컬럼명2', hue='컬럼명3(데이터가 이산형인 경우)')
plt.show())
swarmplot (떼, 무리)
데이터가 몰려있는 경우에 옆으로 쌓이는 그래프를 그리고 있어 stripplot보다 보기가 편하다는 장정이 있습니다.

sns.swarmplot(data=데이터프레임명, x='컬럼명1', y='컬럼명2', hue='컬럼명3(데이터가 이산형인 경우)')
plt.show())
Box plot (수염 상자 그림)


sns.boxplot(data=데이터프레임명, x='컬럼명1', y='컬럼명2')
plt.show()
# order로 순서 설정 가능
sns.boxplot(data=데이터프레임명, x='컬럼명1', y='컬럼명2', order = ['MON','TUE','WED','THU','FRI','SAT','SUN'])
plt.show()
Violinplot

sns.violinplot(data=데이터프레임명, x='컬럼명1', y='컬럼명2')
plt.show()중간의 하얀 점이 중위수이며, 두꺼운 검정색의 선의 범위가 사분위수 범위입니다.
히스토그램 (Histogram)
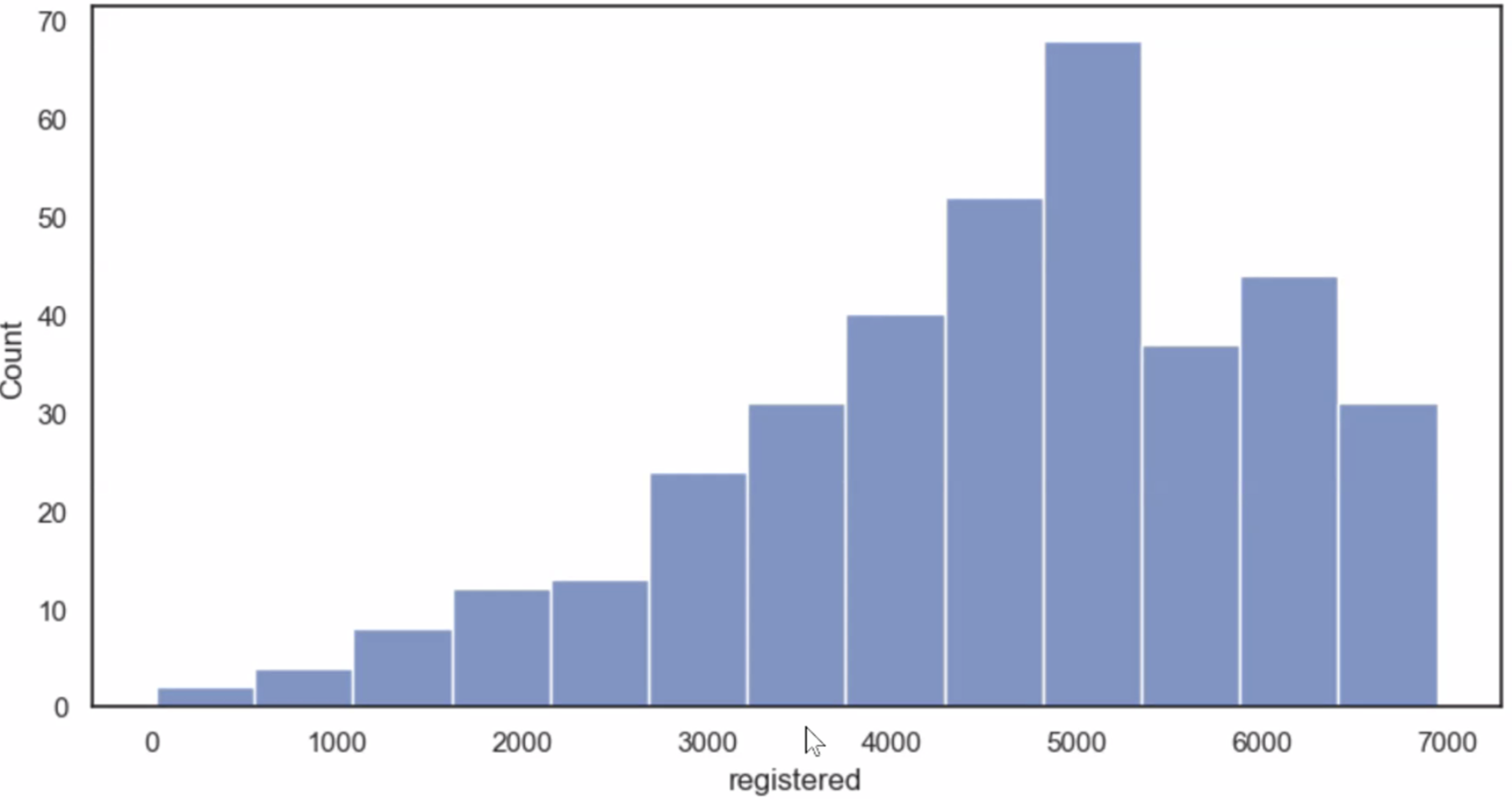

sns.histplot(data=데이터프레임명, x='컬럼명')
plt.show()Matplolib과 달리 Seaborn 라이브러리는 빈의 개수를 스스로 알맞게 조정해서 그래프를 그립니다.(Matplolib 기본값 10개)
물론 bin의 개수를 지정할 수 있습니다.
sns.histplot(data=데이터프레임명, x='컬럼명', hue='컬럼명(데이터가 이산형인 경우)', multiple='stack')
plt.show()히스토그램에서도 hue를 통해 범주별로 나누어 분포를 확인할 수 있고, 보기 어려울때 multiple='stack'을 활용하여 그래프를 보기 쉽게 그릴 수 있습니다.
KDE plot

sns.kdeplot(data=데이터프레임명, x='컬럼명')
plt.show()Matplolib에서 kde그래프를 그릴 때와 같이 bw_method를 활용하여 그래프를 자세하게 그릴 수 있습니다.
산점도 (Scatter Plot)
두 변수 간의 연관성을 파악하기 위해 사용합니다.
- 어떤 값이 변할 때 다른 값도 변화한다면 두 값은 서로 상관관계가 있다고 합니다.
- 상관계수 : 상관관계를 구체적인 수치로 표현한 것
- -1과 1사이의 값을 가진다.
- 상관계수가 0이면 두 값 사이에 상관관계가 없다.
- 상관계수가 0보다 크면 어떤 값이 커질 때 다른 값도 함께 커진다.(양의 상관관계)
- 상관계수가 0보다 작으면 어떤 값이 커질 때 다른 값은 작아진다.(음의 상관관계)
- 상관관계의 절댓값이 1에 가까울수록 상관관계가 강하다.

sns.scatterplot(data=데이터프레임명, x='컬럼명1', y='컬럼명2')
plt.show()
regplot (regression plot)
산점도에 회귀선이 추가된 그래프의 형태로 두 변수의 관계를 하나의 선으로 표현합니다.

sns.regplot(data=데이터프레임명, x='컬럼명1', y='컬럼명2')
plt.show()
상관계수 (Correlation Coefficient)
# 상관계수 구하기
데이터프레임명.corr()
# 상관계수 계산은 수치형 데이터끼리만 가능하다
# 데이터프레임에 범주형 데이터도 속해있을 경우 numeric_only=True를 지정해주어야 오류가 발생하지 않는다.
데이터프레임명.corr(numeric_only = True)
# 상관계수를 구한 뒤에 특정 컬럼만의 상관계수를 확인하고 싶다면
데이터프레임명.corr(numeric_only = True)['컬럼명']
# 상관계수를 내림차순으로 확인하고 싶다면
데이터프레임명.corr(numeric_only = True)['컬럼명'].sort_values(ascending=False)히트맵을 이용한 상관계수 시각화

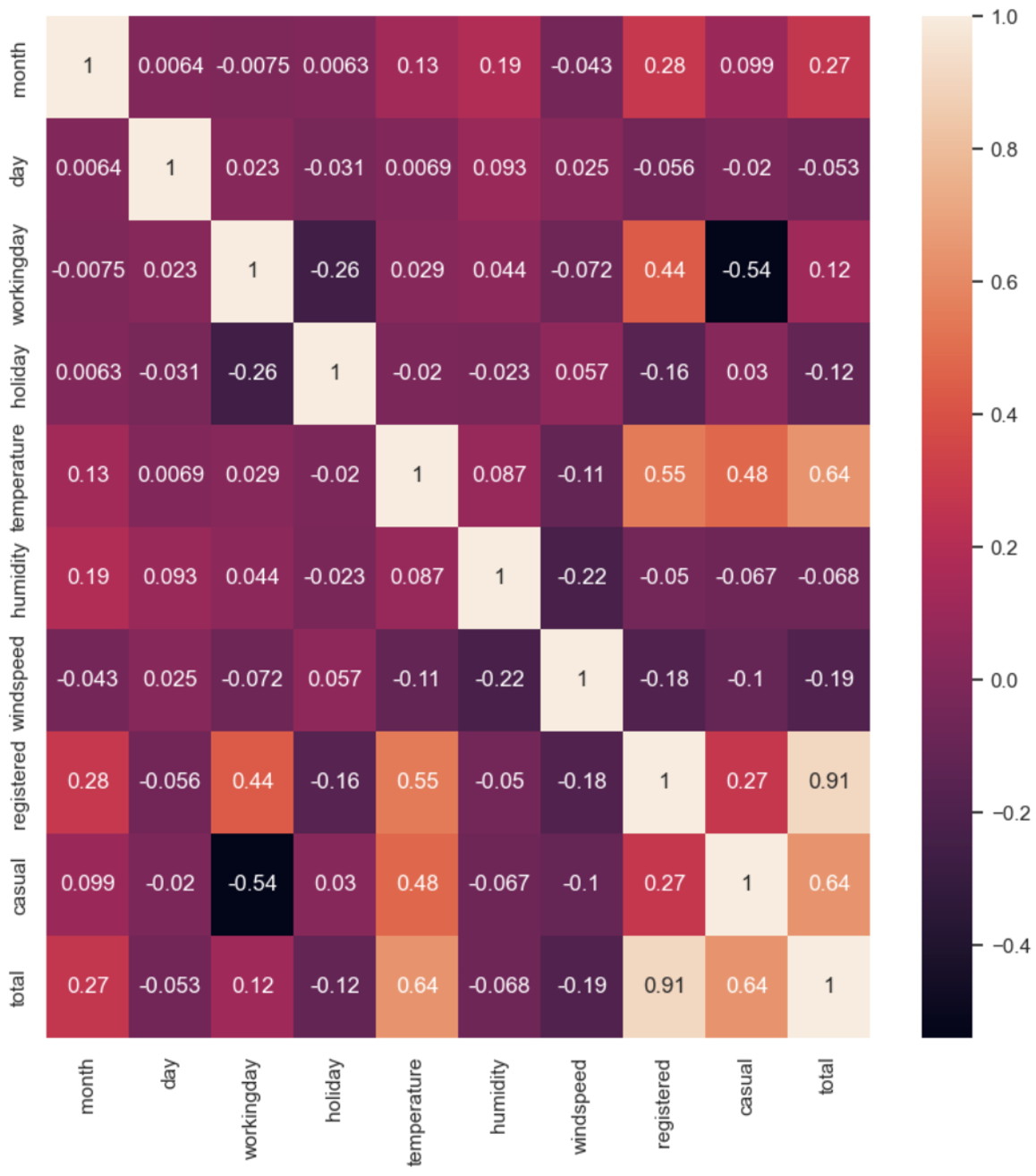
# 히트맵 그리기 (데이터프레임에 범주형 데이터도 함께 있는 경우)
sns.heatmap(데이터프레임명.corr(numeric_only=True))
plt.show()
# 히트맵에 상관계수를 시각화하고 싶을 때 annot=True를 사용한다.
sns.heatmap(데이터프레임명.corr(numeric_only=True), annot=True)
plt.show()
상관계수 개념 심화
상관 계수 중에서 가장 널리 사용되는 것은 피어슨 상관 계수로 -1부터 1 사이의 값을 가집니다.
상관 계수가 1에 가까울수록 두 변수는 강한 양의 상관관계가 있고, 반대로 상관 계수가 -1에 가까울수록 강한 음의 상관관계가 있다고 볼 수 있습니다.
피어슨 상관 계수 값을 계산하려면 두 변수의 '공분산(covariance)'이라는 값을 구해서, 공분산을 각 변수의 표준 편차의 곱으로 나눠 줘야 합니다.
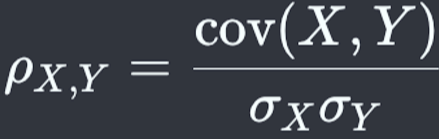
공분산은 두 변수 간의 관계의 방향성과 강도를 측정할 때 사용할 수 있는 통계 값입니다.
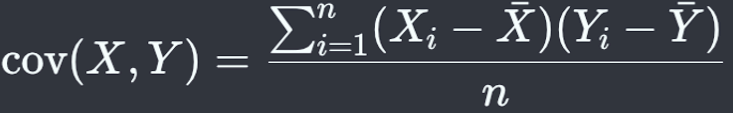
공분산을 구하려면 각 값과 해당 변수의 평균값 간의 편차를 곱하여 모두 더한 뒤, 데이터의 총 개수로 나눠 주면 됩니다.
하나의 변수가 증가할 때 다른 변수도 증가하는 경향이 있다면 공분산 값은 양수가 되고, 반대로 하나의 변수가 증가할 때 다른 변수는 감소한다면 공분산 값은 음수가 됩니다.
얼핏 보면 개념 자체는 상관 계수와 거의 비슷해 보이지만, 공분산 값의 크기는 변수의 단위에 큰 영향을 받는다는 한계가 있습니다.(단위에 따라 공분산 값의 범위가 크게 달라진다는 뜻)
따라서 공분산 값 만으로는 상관관계의 강도를 객관적으로 비교하고 해석하기가 어렵습니다.
공분산 값이 크게 나왔을 때, 정말로 상관관계가 커서 그런 건지, 단지 변수의 단위 때문에 숫자가 커서 그런 건지 판단할 수가 없기 때문입니다.
피어슨 상관 계수는 이런 공분산을 각 변수의 표준 편차의 곱으로 나눠서, -1에서 1 사이의 값을 가지도록 만듭니다.
즉, 변수의 단위에 관계없이 상관관계의 방향과 강도를 좀 더 객관적으로 비교할 수 있습니다.
이번 글에서는 Seaborn 라이브러리 / 막대 그래프 / 선 그래프 / 그래프 꾸미기 / stripplot / swarmplot / Box plot / Violin plot / 히스토그램 / KDE plot / 산점도 / regplot / 상관계수 / heatmap이 포함된 내용을 정리했으며, 데이터 분석과 데이터를 다루는 경우에 모두 필수적인 개념들로 꼭 잊지 말고 알아가야 하는 내용인 것 같습니다.
글 읽어주셔서 감사합니다.
출처 및 참고자료 : 코드잇 사이트 강의 '기초 통계와 데이터 시각화' https://www.codeit.kr/topics/statistics-and-visualization
'프로그래밍 언어 > Python' 카테고리의 다른 글
| [파이썬 개념 정리 10] 객체와 클래스 개념 정리 (0) | 2024.07.18 |
|---|---|
| [파이썬 개념 정리 9] 맥 운영체제에서 파이썬 환경 구축 내용 정리 (0) | 2024.07.15 |
| [파이썬 개념 정리 7]통계의 기본과 파이썬을 이용한 데이터 시각화 개념 (2) | 2024.07.05 |
| [파이썬 개념 정리 6]Pandas 라이브러리 개념 정리 (0) | 2024.06.29 |
| [파이썬 개념 정리 6]Matplotlib 라이브러리 개념 정리 (0) | 2024.06.29 |
데이터 분석을 공부하고 카페를 열심히 돌아다니는 이야기
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!
![[파이썬 개념 정리 7]통계의 기본과 파이썬을 이용한 데이터 시각화 개념](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbnKQGb%2FbtsInkvTu8w%2FvcVWn5IKWInWuskb9B2iQK%2Fimg.png)